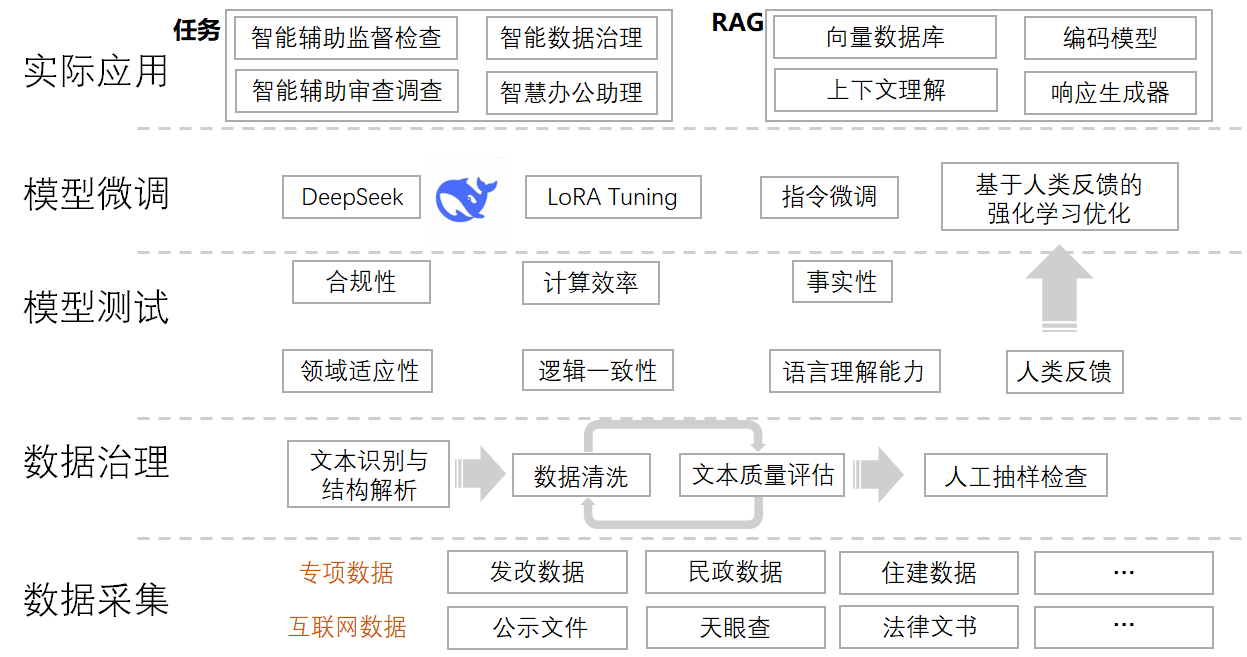
一、数据采集:采集发改数据、民政数据等内部专项数据,以及公示文件、法律文书、天眼查等互联网公开数据,形成纪检监察领域的专有数据库。
二、数据治理:对已采集的数据开展文本解析与结构化处理,进行数据清洗和数据质量评价,采用循环迭代方式,直至数据质量达标。最终实施人工抽样检查,确保数据治理质量。
三、模型测试: 对模型性能进行系统化测试,评估模型的事实性、合规性、逻辑一致性和语言理解能力,构建纪检监察领域模型评价体系。
四、模型微调: 以DeepSeek为基座模型,采用LoRA、指令微调与基于人类反馈的强化学习(RLHF)三种先进的微调技术,全面提升模型在纪检监察场景下的表现。
五、模型应用:结合RAG(检索增强生成)与纪检监察垂直大模型,实现智慧办公助理、智慧审查等功能,以实现精准执纪、高效监察。